近期,计算机语言学和自然语言处理领域国际顶级学术会议Annual Meeting of the Association for Computational Linguistics 2025(ACL2025,中国计算机学会推荐国际学术会议A类,CCF-A类)录用结果陆续揭晓,华东理工大学信息科学与工程学院阮彤、刘井平、叶琪、翟洁等老师带领的自然语言处理与大数据实验室团队共5篇最新成果被接收,其中包括2篇主会长文和3篇Findings长文。研究内容覆盖:Text-to-Elasticsearch转换引擎,多模态大模型空间关系推理,基于大模型的医学临床路径发现,基于大模型的医疗质控,开放式问答自动评估等。

### 01
论文标题:Text-to-ES Bench: A Comprehensive Benchmark for Converting Natural Language to Elasticsearch Query
论文作者:薛冬阁,蒲志立,夏振涛,孙红利,侯瑞辉,余广涯,林宇翩,范勇琪,刘井平,阮彤
录用类型:ACL 2025 Main
主要工作和贡献:Elasticsearch(ES)是一款分布式RESTful搜索引擎,专为大规模长文本搜索场景优化。我们首次提出了创新的语义解析任务,文本到ES查询(text-to-ES)。具体而言,我们提出了text-to-ES基准测试,包含两个数据集:1)大型ES数据集(LED),schema-free数据库,包含26,207个文本-ES查询对;2)基于33.4GB schema-fixed数据集(BirdES),包含10,926个text-ES查询对。在与14个先进LLM及6个基于代码的LLM对比中,我们训练的模型在LED数据集上以15.64%的优势超越DeepSeek-R1,在BirdES数据集上达到DeepSeek-R1性能的78%。
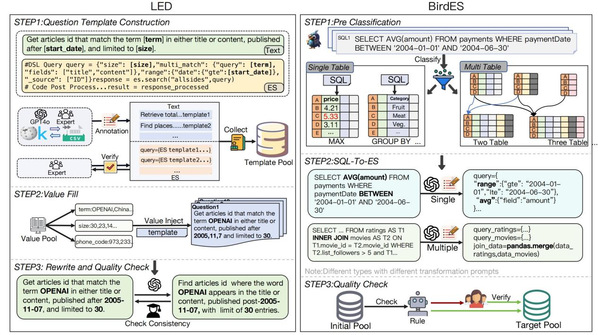
图标题Text-to-ES数据构建pipline
### 02
论文标题:Can Multimodal Large Language Models Understand Spatial Relations?
论文作者:刘井平, 刘子言, 岑哲栋, 周妍, 邹奕楠, 张维彦, 蒋海云, 阮彤
录用类型:ACL 2025 Main
主要工作和贡献:空间关系推理是多模态大语言模型(MLLMs)理解客观世界的关键能力。针对现有基准依赖边界框、脱离真实世界标注、忽略视角转换且允许模型仅凭先验知识作答等问题,我们构建了SpatialMQA数据集。该数据集基于COCO2017并经人工高质量标注,包含5392个样本,旨在弥补上述缺陷,促使MLLMs更专注于客观世界理解。我们评估了一系列主流MLLMs,发现其最高准确率仅为48.14%,远低于人类的98.40%。本项工作还提供了深入的实验分析,为未来研究指明了方向。
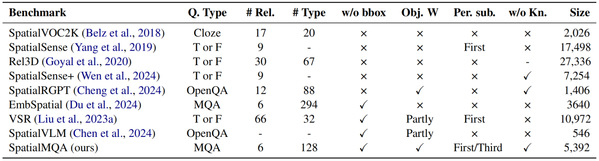
图标题多模态空间关系推理基准概述,SpatialMQA弥补了以往基准的不足
### 03
论文标题:EMRs2CSP : Mining Clinical Status Pathway from Electronic Medical Records
论文作者:陈逸飞,侯瑞辉,刘井平,阮彤
录用类型:ACL 2025 Findings
主要工作和贡献:本研究中,我们的目标是从电子病历中抽取出包含更多医学信息的临床路径,它具有时序信息、患者状态信息、路径决策逻辑。为了实现这一目的,我们提出了一种新的临床路径表示方法:临床状态路径,并且我们设计了一种基于大模型的pipeline用来从电子病历中抽取临床状态路径。通过这种方法,我们构建了完整的乳腺癌专病临床状态路径,在实验中,人工和自动评估证明了我们的表示方法的优越性和我们抽取方法的准确性。
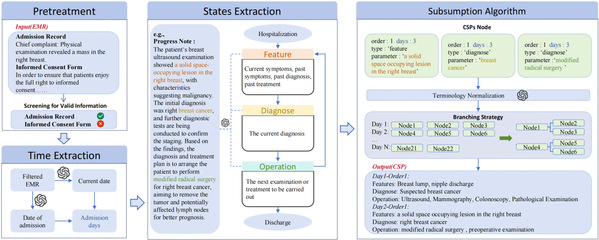
图标题基于大模型的临床状态路径抽取pipeline框架
### 04
论文标题:CMQCIC-Bench: A Chinese Benchmark for Evaluating Large Language Models in Medical Quality Control Indicator Calculation
论文作者:余广涯,李艳豪,蒋宗颖,金宇雄,戴丽,林宇翩,侯瑞辉,张维彦,范勇琪,叶琪,刘井平,阮彤
录用类型:ACL 2025 Findings
主要工作和贡献:本文(1)首次提出医疗质量控制指标计算任务,并构建基于中文电子病历的开源数据集CMQCIC-Bench,包含785个实例和76项指标;(2)提出半自动化规则表示增强方法,创新性设计基于临床事实的推理规则(CF-IR)框架,实现临床事实验证与推理规则解耦;(3)对20个代表性大语言模型(包括通用与医疗大模型)展开系统性实验,结果表明:在MQCIC任务中,CF-IR方法相较传统思维链推理方法准确率提升1.45%,最高可达95.54%的领先水平。这一突破性进展为医疗质量控制的智能化应用奠定了关键技术基础。
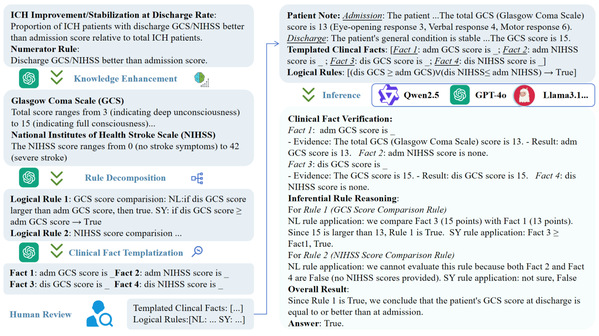
图标题 基于大模型的规则增强(左)与基于临床事实的推理规则(右)框架
### 05
论文标题:MinosEval: Distinguishing Factoid and Non-Factoid for Tailored Open-Ended QA Evaluation with LLMs
论文作者:范勇琪,汪雅婷,王冠栋,翟洁,刘井平,叶琪,阮彤
录用类型:ACL 2025 Findings
主要工作和贡献:本文提出了MinosEval,一种面向开放式问答的评估方法,通过区分事实类与非事实类问题实现精细化评估。前者采用自适应要点评分策略,动态匹配关键信息;后者则设计实例感知的列表排序机制,增强评估的对比性。相比传统指标和现有LLM评估方法,MinosEval提升人工评估一致性(约23%)并提供了透明的评分依据。此外,我们构建了包含多样化候选答案的评测数据集,弥补了社区资源的不足。方法提供了更精准、可解释的开放式问题评估方案,也可用于探索更精细的大模型过程奖励设计。
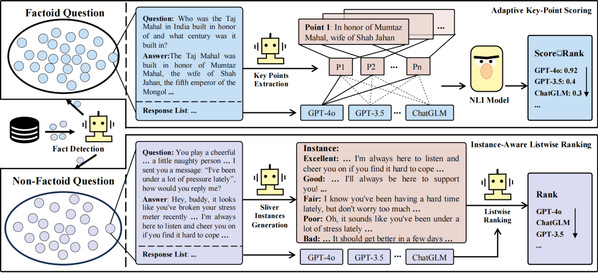
图标题 MinosEval评估流程:区分事实类与非事实类问题、自适应要点评分与具实例感知的列表排序
近年来,自然语言处理与大数据实验室团队专注于自然语言处理(NLP)与大语言模型的研究,陆续在ACL、AAAI、IEEE TKDE、AI、WWW、IPM等国内外顶级会议和期刊上发表了多篇高水平论文,部分研究成果已成功应用于医疗、电商等领域。团队的研究工作得到了国家重点研发计划、国家自然科学基金青年科学基金、上海市青年科技英才扬帆计划和上海市基础研究特区计划等项目的资助支持,充分展现了华东理工大学信息科学与工程学院在人工智能前沿领域的科研实力,进一步提升了学校在相关领域的学术声誉和影响力。