近期,华东理工大学信息科学与工程学院自然语言处理与大数据实验室团队在计算机语言学和自然语言处理领域国际顶级学术会议Annual Meeting of the Association for Computational Linguistics 2024(ACL2024,中国计算机学会推荐国际学术会议A类,CCF-A类)上,分别以“Unexpected Phenomenon: LLMs' Spurious Associations in Information Extraction(意想不到的现象:大规模语言模型在信息提取中的虚假关联)”和“RRNorm: A Novel Framework for Chinese Disease Diagnoses Normalization via LLM-Driven Terminology Component Recognition and Reconstruction(RRNorm:一种LLM驱动识别和重构术语组成成分的中文疾病诊断标准化新框架)”为题,接收发表2篇关于大模型信息抽取中的幻觉和医疗术语归一化的最新成果。
针对LLM在信息抽取任务上的幻觉问题,研究团队在论文“Unexpected Phenomenon: 大规模语言模型在信息提取中的虚假关联”发现了一个有趣现象:不同参数规模的LLM在信息抽取任务上存在虚假关联。以关系提取任务为例,即使给定的关系(标签)在语义上与预定义的原始关系无关,LLM仍能准确识别实体对。为了获取这些标签,我们在本研究中设计了两种策略,包括前向标签扩展和后向标签验证。我们还利用扩展标签来提高模型性能。我们的实验表明,无论是在中文还是英文数据集中,不同规模的LLM都会一致地出现虚假关联现象。此外,使用扩展标签显著提高了LLM在信息提取任务中的性能。在SciERC、ACE05和DuEE数据集上,F1分数分别提高了9.55%、11.42%和21.27%。
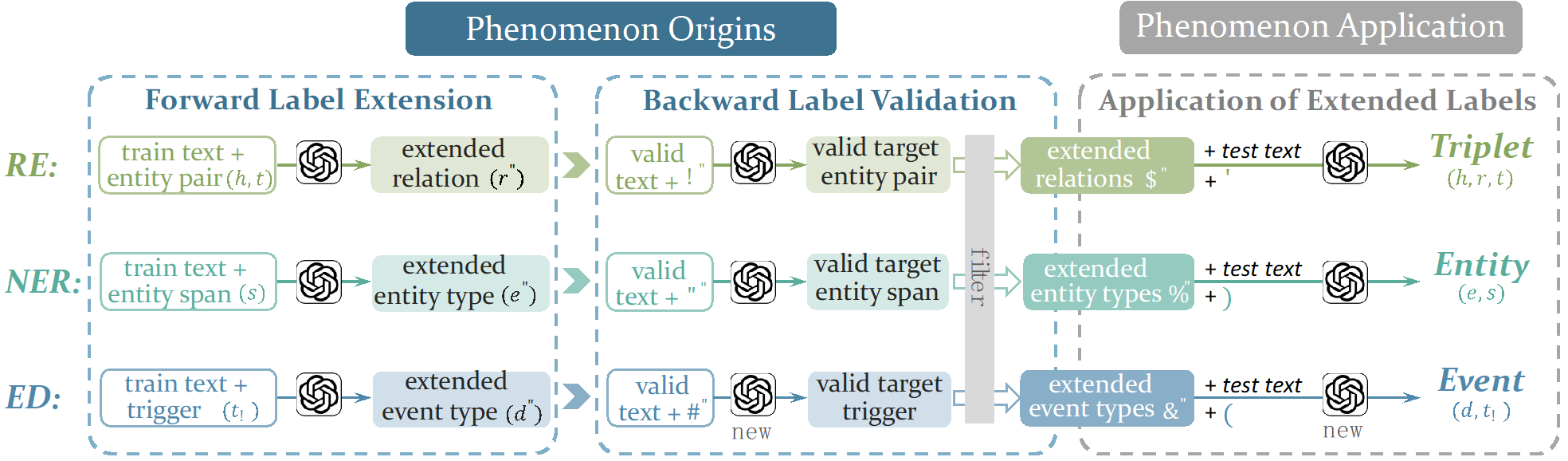
图片说明:LLM在信息抽取任务中虚假关联现象的起源与应用框架图
针对中文临床疾病诊断术语标准化任务中存在的表达多样化和多重蕴含问题,研究团队在“RRNorm:一种LLM驱动识别和重构术语组成成分的中文疾病诊断标准化新框架”中创新地提出了一种术语组成成分识别和重构策略,利用大语言模型(LLM)的推理能力自动识别疾病诊断短语的组成成分,并转换为多个原子短语。此外,研究团队基于主流的“召回和精排”框架,将术语组成成分识别和重构策略的优势应用于任务流:在召回阶段,设计了一种针对原子短语的采样算法,消除了多重蕴含问题带来的短语含义混淆;在精排阶段,利用注意力机制融入组成成分的信息作为指导,提高了精排阶段的准确率。这项研究成果有效地提高了中文疾病诊断标准化任务的性能,在CHIP-CDN数据集上达到了出色的水平。

图片说明:LLM驱动识别和重构术语组成成分的中文疾病诊断标准化框架图
上述发表于国际自然语言处理顶级会议ACL2024的成果第一作者分别是博士生张维彦与博士生范勇琪,通讯作者均为刘井平老师和阮彤教授等。此外,自然语言处理与大数据实验室团队在前期围绕NLP,陆续在AAAI,IEEE TKDE,IPM,INS等发表了多篇高水平论文。相关成果得到国家重点研发计划、国家自然科学基金青年科学基金、上海市青年科技英才扬帆计划资助项目和上海市基础研究特区计划项目的支持,展现了华东理工大学信息科学与工程学院在人工智能前沿领域的最新研究成果,提升了我校在相关领域的学术影响力。